


목차
제네릭과 컬렉션
13.1 제네릭 프로그래밍
- 다양한 종류의 데이터를 처리할 수 있는 클래스와 메소드를 작성하는 기법
- Object 타입의 변수를 사용하는 것보다 안전하고 사용하기 쉽다.
- 제네릭을 한마디로 말하자면 클래스를 정의할 때, 클래스 안에서 사용되는 자료형(타입)을 구체적으로 명시하지 않고 T와 같이 기호로 적어놓는 것
- 즉, 자료형을 클래스의 매개 변수로 만든 것
이전의 방법
- 다형성 → 객체를 Object 타입으로 받아서 처리하는 방법
- 문제점
- 데이터를 꺼낼 때 마다 형 변환 해주어야 한다.
- 형변환을 잘못하면 오류 발생
제네릭을 이용한 방법
- 제네릭 클래스는 타입을 변수로 표시한다. 이것을 타입 매개 변수(type parameter)라고 하는데 객체 생성 시에 프로그래머에 의해 결정된다.
- 제네릭 클래스 설계시 기존 방법의 Object 자리에 타입 매개 변수를 넣어준다.
제네릭 메소드
- 일반 클래스의 메소드에서도 타입 매개 변수를 사용하여서 제네릭 메소드를 정의 할 수 있다.
public static <T> T getLat(T[] a) {
return a[a.length - 1];
}사용할때는 일반 메소드 처럼 사용 가능
타입 매개 변수의 표기
한 가지 주의할 점은 제네릭 클래스는 여러 개의 타입 매개 변수를 가질 수 있으나 타입의 이름은 클래스나 인터페이스 안에서 유일하여야 한다. 관례에 의하여, 타입의 이름은 하나의 대문자료 한다. 이것은 변수의 이름과 타입의 이름을 구별할 수 있게 하기 위함이다. 일반적으로 많이 사용되는 이름들은 다음과 같다.
E - Element(요소 : 자바 컬렉션 라이브러리에서 많이 사용된다.)
K - Key
N - Number
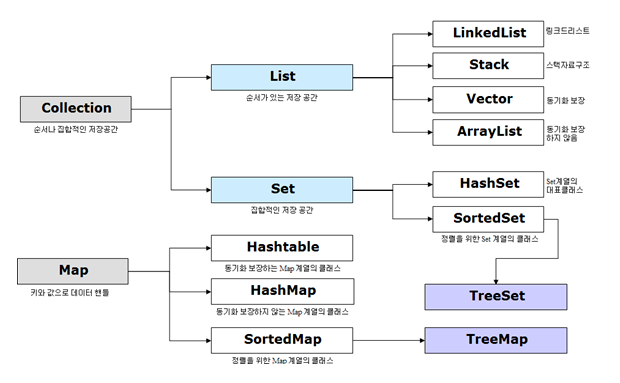
13.2 컬렉션이란?
- 애플리케이션의 작성을 도와주는 중요한 도구. 자료를 저장하기 위한 구조
- 많이 사용되는 자료 구조 : list, stack, queue, set, hash table 등
- 컬렉션은 제네릭 기법으로 구현되어 있기 때문에 어떠한 타입의 데이터도 저장할 수 있다.
컬렉션의 종류
- 컬렉션 인터페이스와 컬렉션 클래스로 나누어짐 → 각자 필요에 맞추어 인터페이스를 자신의 클래스로 구현할 수도 있다.
컬렉션의 특징
- 컬렉션은 제네릭을 사용한다.
- 컬렉션에는 int나 double과 같은 기초 자료형은 저장할 수 없다.
기초 자료형을 클래스로 감싼 랩퍼 클래스인 Integer나 Double은 사용할 수 있다. - 기본 자료형을 저장하면 자동으로 랩퍼클래스의 객체로 변환된다. 오토박싱
컬렉션 인터페이스의 주요 메소드
| 메소드 | 설명 |
| boolean isEmpty() | 공백 상태이면 true 반환 |
| boolean contains(Object obj) | obj를 포함하고 있으면 true 반환 |
| boolean containsAll(Collection<?> c) | |
| boolean add(E element) | 원소를 추가 |
| boolean addAll(Collection<? extends E> from) | |
| boolean remove(Object obj) | 원소를 삭제 |
| boolean removeAll(Collection<?> c) | |
| boolean retainAll(Collection<?> c) | |
| void clear() | |
| Iterator<E> iterator() | 원소 방문 |
| Stream<E> stream() | |
| Stream<E> parallelStream() | |
| int size() | 원소의 개수 반환 |
| Object[] toArray() | 컬렉션을 배열로 변환 |
| <T> T[] toArray(T[] a) |
- 이들 메소드는 Collection 인터페이스를 상속받아서 구현한 모든 클래스가 사용할 수 있다.
컬렉션의 모든 요소 방문하기
String a[] = new String[] {"A", "B", "C", "D", "E"};
List<String> list = Arrays.asList(a);- 전통적인 for 문
for (int i=0; i<list.size(); i++)
System.out.println(list.get(i));- for-each 구문
for (String s : list)
System.out.println(s);- 반복자(Iterator) 사용
- 반복자는 특별한 타입의 객체로 컬렉션의 원소들을 접근하는 것이 목적
- hasNext() : 아직 방문하지 않은 원소가 있으면 true 반환
- next() : 다음 원소를 반환
- remove() : 최근에 반환된 원소를 삭제
String s;
Iterator e = list.iterator();
while(e.hasNext())
{
s = (String)e.next(); // 반복자는 Object 타입을 반환!!
System.out.println(s);
}- Stream 라이브러리를 이용
list.forEach((n) -> Systme.out.println(n));13.3 벡터
- 가변 크기의 배열을 구현하고 있다.
- 제네릭 기법을 사용하고 있으므로 어떤 타입의 객체라도 저장할 수 있다.
- 스레드 간의 동기화를 지원 → 멀티 스레드 상황에서 좋음
13.4 ArrayList
- 가변 크기의 배열을 구현하는 클래스이다
- Vector와 아주 유사하다.
- 동기화를 지원하지 않기 때문에 Vector보다 성능이 우수하다
ArrayList의 기본 연산
- ArrayList를 생성하려면 타입 매개 변수를 지정하여야 한다.
ArrayList<T> list = new ArrayList<>();- add() : 데이터 저장
- set() : 데이터 변경
- remove() : 데이터 삭제
- size() : 저장된 원소의 개수
- contains() : 특정 값이 리스트에 있는지 확인
배열을 리스트로 변경하기
List<String> list = Arrays.asList(new String[size]);13.5 LinkedList
- ArrayList의 단점 : 데이터의 삽입이나 삭제가 빈번하게 발생하는 경우 삽입, 삭제시 뒤의 원소들이 이동을 해야함
→ LinkedList를 사용해야함 - 각 원소를 링크로 연결, 각 원소들은 다음 원소를 다음 원소를 가리키는 링크를 저장
- 연결 리스트에서는 중간에 원소를 삽입하거나 삭제할 때 원소의 링크값만 변경하면 된다.
- 단점 : 인덱스를 가지고 접근하는 연산은 ArrayList가 더 빠름
ArrayList vs LinkedList
ArrayList는 인덱스를 가지고 원소에 접근할 경우, 항상 일정한 시간만 소요된다. ArrayList는 리스트의 각각의 원소를 위하여 노드 객체를 할당할 필요가 없다. 또 동시에 많은 원소를 이동하여야 하는 경우에는 System.arraycopy()를 사용할 수 있다.
만약 리스트의 처음에 빈번하게 원소를 추가하거나 내부의 원소 삭제를 반복하는 경우에는 LinkedList를 사용하는 것이 낫다. 이들 연산들은 LinkedList에서는 일정한 시간만 걸리지만 ArrayList에서는 원소의 개수에 비례하는 시간이 소요된다. 그러나 문제는 인덱스를 가지고 접근 할 때는 반대가 된다. 따라서 성능에서 손해를 보게 된다. 따라서 LinkedList를 사용하기 전에 응용 프로그램을 LinkedList와 ArrayList를 사용하여 구현한 후에 실제 시간을 측정하여 보는 것이 좋다. 일반적으로는 ArrayList가 빠르다.
ArrayList는 한 가지 튜닝 매개 변수를 가지고 있다. 즉 초기 용량(initial capacity)이 그것으로 확장되기 전에 ArrayList가 저장할 수 있는 원소의 개수를 말한다. LinkedList는 튜닝 매개 변수가 없지만 대신 몇 가지의 메소드를 가지고 있다. addFirst(), getFirst(), removeFirst(), addLast(), getLast(), removeLast() 들이 여기에 해당한다.
13.6 Set
- 순서에 상관없이 데이터만 저장하고 싶은 겨우 사용
- 데이터의 중복만을 막도록 설계되어 있다.
- HashSet
- 해쉬 테이블에 원소를 저장하기 때문에 성능면에서 가장 우수하다.
- 원소들의 순서가 일정하지 않다
- TreeSet
- 레드-블랙 트리에 원소를 저장한다.
- 값에 따라 순서가 결정되지만 HashSet보다 느리다
- LinkedHashSet
- 해쉬 테이블과 연결 리스트를 결합한 것으로 원소들의 순서는 삽입되었던 순서와 같다.
- 약간의 비용을 들여서 HashSet의 문제점인 순서의 불명확성을 제거한 방법
합집합과 교집합
- 합집합 : addAll()
- 교집합 : retainAll()
13.7 Map
- 키-값을 하나의 쌍으로 묶어서 저장하는 자료구조
- 중복된 키를 가질 수 없다.
- Collection 인터페이스를 사용하지 않고 별도의 Map이라는 이름의 인터페이스가 제공됨
- HashMap : 해싱 테이블에 데이터를 저장
- TreeMap : 탐색 트리에 데이터를 저장
- put() : 데이터 저장
- get() : 값 추출
Map의 모든 요소 방문하기
1. for-each 구문과 keySet()을 사용하는 방법
for (String key: map.keySet()) {
System.out.println("key = " + key + ", value = " + map.get(key));
}
2. 반복자를 사용하는 방법
Iterator<String> it = map.keySet().iterator();
while (it.hasNext()){
String key = it.next();
System.out.println("key = " + key + ", value = " + map.get(key));
}
3. Stream 라이브러리를 사용하는 방법
map.forEach ( (key, value) -> {
System.out.println("key = " + key + ", value = " + value);
}13.8 Queue
- 데이터를 처리하기 전에 잠시 저장하고 있는 자료구조
- tail에 원소를 추가하고 head에서 원소를 삭제한다.
- FIFO 형식으로 저장
- 우선 순위 큐 : 우선순위에 따라서 저장
Queue 메소드
- add() : 새로운 원소의 추가가 큐의 용량을 넘어서지 않으면 원소를 추가
만약 용량을 넘어가면 IllegalStateException 발생 - offer() : 원소 추가에 실패하면 false 반환
- remove() : 큐의 처음에 있는 원소를 제거하거나 가져옴
만약 큐에 원소가 없으면 NoSuchElementException 발생 - poll() : 원소가 없으면 null 반환
- element() : 큐의 처음에 있는 원소를 삭제하지 않고 가져옴
만약 큐에 원소가 없으면 NoSuchElementException 발생 - peek() : 원소가 없으면 null 반환
우선 순위 큐
- 무작위로 삽입되었더라도 정렬된 상태로 원소들을 추출한다.
- remove()를 호출할때마다 가장 작은 원소가 추출된다.
13.9 Collections 클래스
- 여러 유용한 알고리즘을 구현한 메소드들을 제공
- 이 메소드들은 제네릭 기술을 사용하여서 작성되었으며 정적 메소드의 형태로 되어 있다.
- 메소드의 첫 번째 매개 변수는 알고리즘이 적용되는 컬렉션이 된다.
정렬
- 데이터를 어떤 기준에 의하여 순서대로 나열하는 것
- Collections 클래스의 정렬은 속도가 비교적 빠르고 안정성이 보장되는 합병 정렬을 이용
- 합병 정렬은 시간 복잡도가 O(nlog(n))이며 특히 거의 정렬된 리스트에 대해서는 상당히 빠르다
- sort() : List 인터페이스를 구현하는 컬렉션에 대하여 정렬을 수행
String 이라면 알파벳 순으로, Date라면 시간 순으로 정렬됨 → Comparable 인터페이스를 구현하기 때문
예제 : 사용자 클래스의 객체 정렬
class Student implements Comparable<Student> {
int number;
String name;
...
...
...
// 현재 객체의 number가 더 크면 음수, 같으면 0, 작으면 양수
public int compareTo(Student s){
return s.number - number;
}
}섞기
- 리스트에 존재하는 정렬을 파괴해서 원소들의 순서를 랜덤하게 만든다.
- Collections.shuffle(list);
탐색
- 리스트 안에서 원하는 원소를 찾는 것
- 리스트가 정렬되어 있지 않다면 모든 원소를 방문(선형 탐색)
- 리스트가 정렬되어 있다면 중간에 있는 원소와 먼저 비교(이진 탐색)
Collections 클래스의 binarySearch 알고리즘은 정렬된 리스트에서 지정된 원소를 이진 탐색한다.
binarySearch()은 리스트와 탐색할 원소를 받는다.
index = Collections.binarySearch(collec, element);
만약 반환값이 양수이면 탐색이 성공한 객체의 위치이고,
collec.get(index)하면 원하는 객체를 얻을 수 있다.
만약 반환값이 음수이면 탐색이 실패한 것이다. 실패하였어도 반환값은 도움이 되는데
int pos = Collections.binarySearch(collec, element);
if (pos < 0) collec.add(-pos-1);
이렇게 삽입될 수 있는 위치를 알아낼 수 있다.
Summary
- 제네릭 프로그래밍(generic programming)이란 다양한 종류의 데이터를 처리할 수 있는 클래스와 메소드를 작성하는 기법이다.
- 제네릭은 클래스를 정의할 때, 클래스 안에서 사용되는 자료형(타입)을 구체적으로 명시하지 않고 T와 같이 기호로 적어놓는 것이다.
- 컬렉션(collection)은 자료를 저장하기 위한 구조이다.
- 많이 사용되는 컬렉션에는 리스트(list), 스택(stack), 큐(queue), 집합(set), 해쉬 테이블(hash table) 등이 있다.
- 벡터(Vetor) 클래스는 java.util 패키지에 있는 컬렉션의 일종으로 가변 크기의 배열(dynamic array)을 구현하고 있다.
- ArrayList도 가변 크기의 배열을 구현하는 클래스이다. ArrayList는 동기화를 하지 않기 때문에 Vector보다 성능은 우수하다.
- 순서에는 상관없이 데이터만 저장하고 싶은 경우에는 집합(Set)을 사용할 수 있다. 집합(set)은 동일한 데이터를 중복해서 가질 수 없다.
- Map은 많은 데이터 중에서 원하는 데이터를 빠르게 찾을 수 있는 컬렉션이다. 다른 언어에서는 딕셔너리(dictionary)라고도 한다.
- Map은 키(key)와 값(value)을 쌍으로 저장한다. 각 키는 오직 하나의 값에만 매핑될 수 있다. 키가 제시되면 Map은 값을 반환한다.
- Collections 클래스는 정렬(Sorting), 섞기(shuffling), 탐색(Searching)과 같은 유용한 알고리즘을 구현한 메소드들을 제공한다.
Programming
1. 동일한 타입의 데이터 2개를 저장하는 SimplePair 클래스를 작성해보자.
SimplePair 클래스를 사용하는 코드
public class SimplePairTest {
public static void main(String[] args) {
SimplePair<String> pair = new SimplePair<String>("apple", "tomato");
System.out.println(pair.getFirst());
System.out.println(pair.getSecond());
}
}
풀이
@Getter
@AllArgsConstructor
public class SimplePair <T>{
private T first;
private T second;
}2. 클래스 MyMath를 작성하여 보자. MyMath에는 평균을 구하는 getAverage() 제네릭 메소드를 추가해 보자
getAverage()는 Integer나 Double과 같은 다양한 타입의 데이터 배열을 받아서 평균을 구할 수 있다.
메소드
public static <T extends Number> double getAverage(ArrayList<T> list) {
double sum = 0;
for (T t : list) {
sum += Double.parseDouble(t + "");
}
return sum/list.size();
}
3. "A","B","C"를 저장하고 있는 HashSet 객체 s1을 생성
"A", "D"를 저장하고 있는 HashSet 객체 s2를 생성
s1과 s2의 합집합과 교집합을 계산해보자
public static void main(String[] args) {
Set<String> s1 = new HashSet<>();
Set<String> s2 = new HashSet<>();
s1.add("A");
s1.add("B");
s1.add("C");
s2.add("A");
s2.add("D");
s1.addAll(s2);
for (String string : s1) {
System.out.print(string + " ");
}
System.out.println();
System.out.println("------------------------");
s1.remove("D");
s1.retainAll(s2);
for (String string : s1) {
System.out.println(string + " ");
}
}
4. 이름들이 모여 있는 문자열 배열이 있다. 이름들이 등장하는 횟수를 Map에 저장해보자.
String names[] = {
new String("Kim"),
new String("Choi"),
new String("Park"),
new String("Kim"),
new String("Kim"),
new String("Park"),
};
출력 예시
Kim : 3회
Choi : 1회
Park : 2회
풀이
public class MapTest {
public static void main(String[] args) {
String names[] = { new String("Kim"), new String("Choi"), new String("Park"), new String("Kim"), new String("Kim"), new String("Park"), };
Map<String, Integer> counts = new HashMap<String, Integer>();
for (String string : names) {
if (counts.containsKey(string)) {
counts.replace(string, counts.get(string) + 1);
} else {
counts.put(string, 1);
}
}
for (String string : counts.keySet()) {
System.out.println(string + " : " + counts.get(string) + "회");
}
}
}

'Java > 교재 정리' 카테고리의 다른 글
| *14 함수형 프로그래밍, 람다식, 스트림 (0) | 2024.07.09 |
|---|---|
| 09 자바 GUI 기초 (0) | 2024.05.03 |
| *16 멀티 스레딩 (1) | 2024.05.02 |
| 08 자바 API 패키지, 예외 처리, 모듈 (0) | 2024.04.27 |
| 07 추상 클래스, 인터페이스, 중첩 클래스 (0) | 2024.04.26 |